
导读
我们之前讲过mysql的压缩行格式, 由于使用得不多,就没具体介绍压缩部分存储的元数据信息,也没看它的溢出页是怎么存储的. 这不恰好就有个需要这俩细节的案例.
压缩行格式
我们先来简单回顾下压缩行格式:
对象 |
大小 |
描述 |
|---|---|---|
FIL_HEADER+PAGE_HEADER |
94 |
页基础信息 |
compressed_data |
x |
元数据信息和压缩的数据 |
uncompressed_data |
y |
未压缩部分的数据 |
….. |
未使用的空间 |
|
overflow page |
溢出页的记录信息, 还是每条20字节 |
|
trx_id+rollptr |
13*n |
事务相关信息 |
page diretory |
2*n |
page dir信息 |
主要是元数据信息部分上次没有讲, 而且如果元数据信息大小判断不对,就直接影响后面的数据读取.元数据信息一般都是记录字段大小是否为空之类的信息,以0x01结尾,但信息本身就可能有0x01,所以不能直接find找结束位置. 规则如下:
- 定长(int等)字段直接记录大小.
- 不超过255字节的变长字段(var)使用0x00表示.
- 超过255字节的变长字段使用126表示允许为空,127表示不允许为空.
- 最后1bit表示是否为空, 1表示为不能为空, 0表示可以为空.
- 连续的非空定长字段会合并.
比如int使用4字节, 则元数据计算方式为 (4<<1)|nullable 非空则为9,空为8. 比较抽象, 我们看个例子吧.
-- 数据准备(注意我这里没有显示设置主键,且未重建表,所以元数据虽然在压缩部分,但数据在未压缩部分)
drop table if exists db1.t20260129_03;
create table db1.t20260129_03(c1 int,c2 int not null, c3 int not null, c4 varchar(20), c5 varchar(20) not null, c6 varchar(300), c7 varchar(300) not null, c8 blob, c9 blob not null) row_format=compressed;
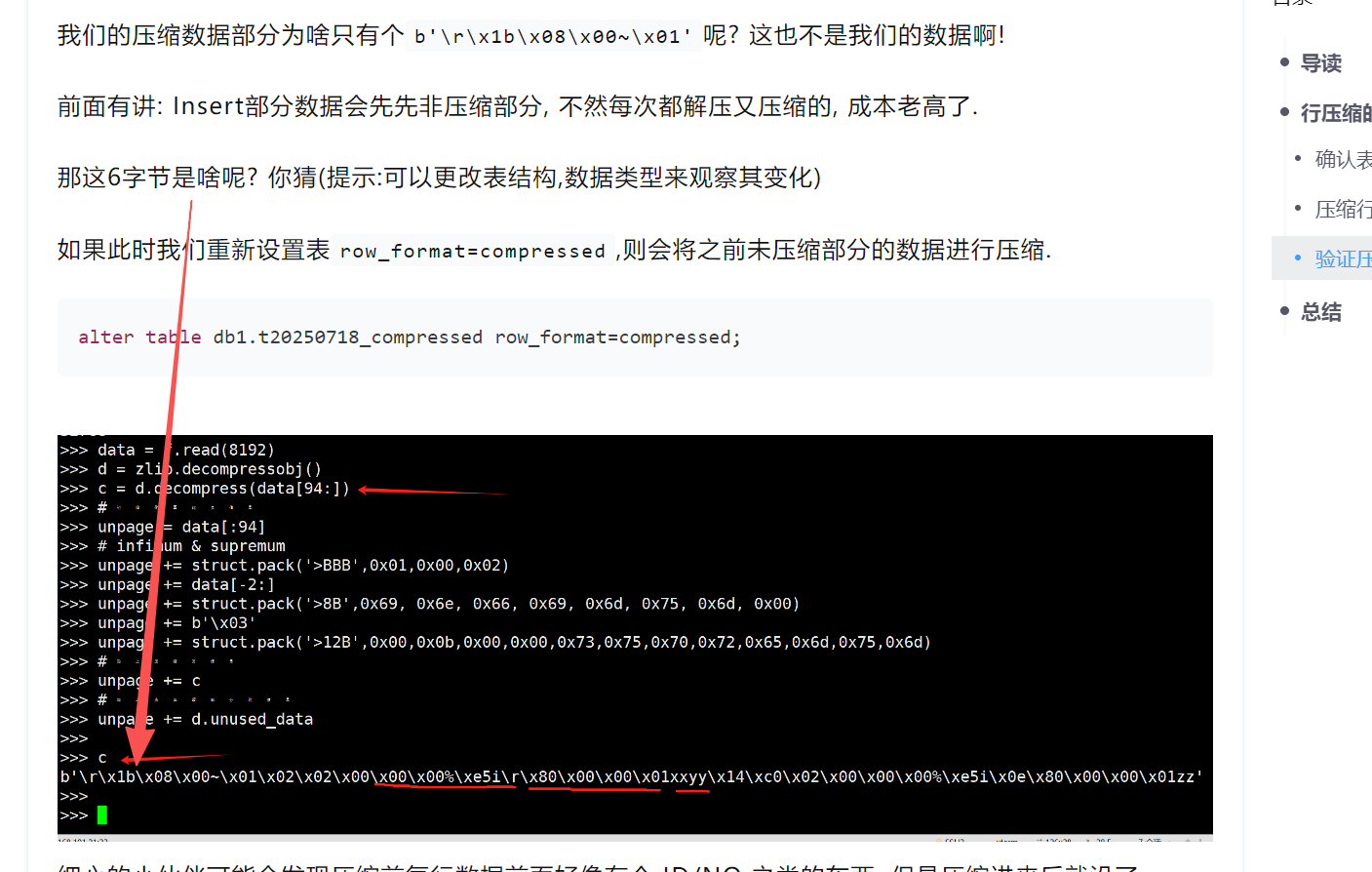
insert into db1.t20260129_03 values(1,2,3,4,5,6,7,8,9);然后我们使用python解析即可.
import struct
import zlib
f = open('/data/mysql_3314/mysqldata/db1/t20260129_03.ibd','rb')
f.seek(4*8192) # 默认压缩是8K
cdata = f.read(8192)
data = zlib.decompress(cdata[94:])
print(data)
print(struct.unpack(f'>{len(data)}B',data))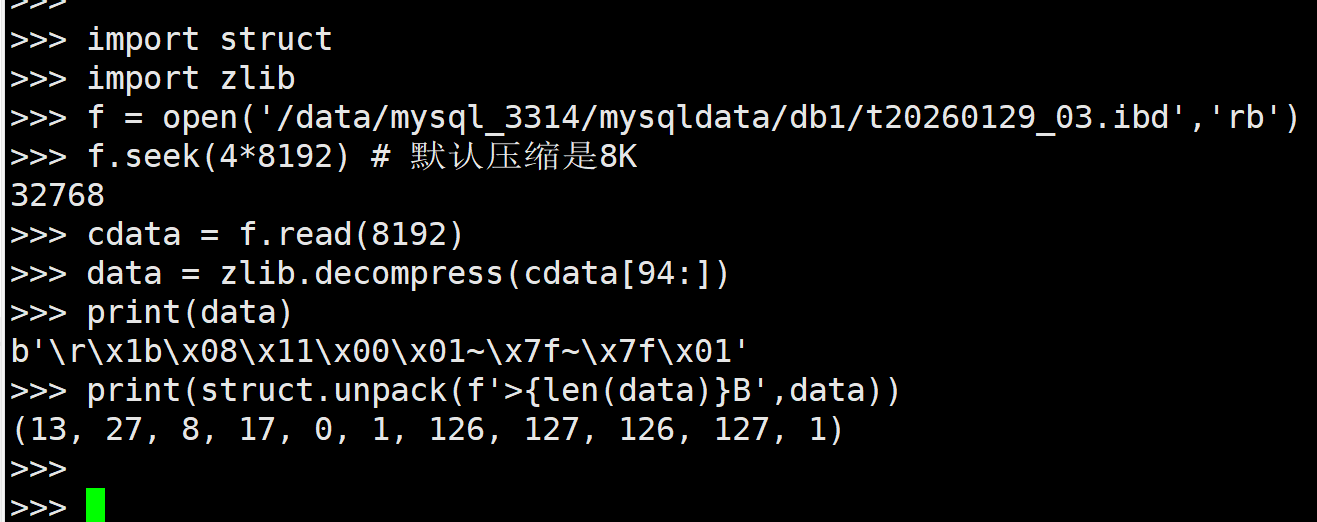
于是得到如下内容:
b'rx1bx08x11x00x01~x7f~x7fx01'
(13, 27, 8, 17, 0, 1, 126, 127, 126, 127, 1)
根据上面的规则我们得到:
二进制 |
10进制 |
size计算 |
非空计算 |
结论 |
|---|---|---|---|---|
b'r' |
13 |
13>>1 = 6 |
'Not null' if 13&1 else 'Null' |
大小为6字节(rowid), 不能为空 |
b'x1b' |
27 |
27>>1 = 13 |
'Not null' if 27&1 else 'Null' |
大小为13字节(trxid+rollptr),不能为空 |
b'x08' |
8 |
8>>1 = 4 |
'Not null' if 8&1 else 'Null' |
大小为4字节(c1),可以为空 |
b'x11' |
17 |
17>>1 = 8 |
'Not null' if 17&1 else 'Null' |
大小为8字节(c2,c3),不能为空 |
b'x00' |
0 |
max 255 |
'Not null' if 0&1 else 'Null' |
不超过255字节的变长字段(c4),可以为空 |
b'x01' |
1 |
max 255 |
'Not null' if 1&1 else 'Null' |
不超过255字节的变长字段(c5),不能为空 |
b'~' |
126 |
over 255 |
'Not null' if 126&1 else 'Null' |
最大超过255字节的长字段(c6),可以为空 |
b'x7f' |
127 |
over 255 |
'Not null' if 127&1 else 'Null' |
最大超过255字节的长字段(c7),不能为空 |
b'~' |
126 |
over 255 |
'Not null' if 126&1 else 'Null' |
最大超过255字节的长字段(c8),可以为空 |
b'x7f' |
127 |
over 255 |
'Not null' if 127&1 else 'Null' |
最大超过255字节的长字段(c9),不能为空 |
b'x01' |
1 |
结束标记 |
看起来比较复杂, 而且用处不大.
压缩行的溢出页格式 FIL_PAGE_TYPE_ZBLOB
我们之前讲过非压缩页的溢出页,5.7的也有讲, 但是没得row_format=compressed的溢出页…. 这不,就来补上了么.
其实row_format=compressed的溢出页(FIL_PAGE_TYPE_ZBLOB)非常简单, 就单纯的流式压缩,没得啥结构(除了比较固定的38字节fil_header). 大概如下图:
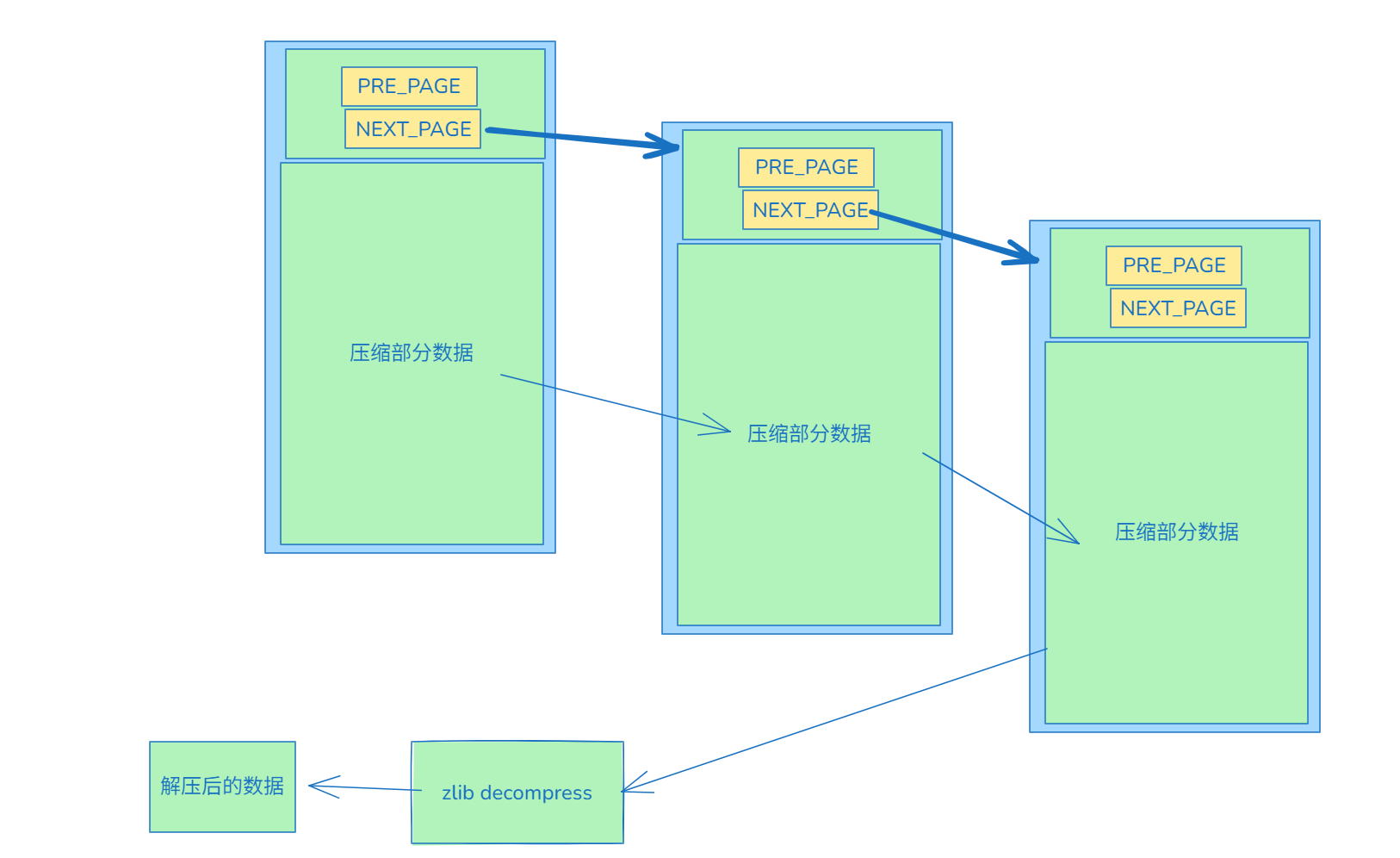
使用python代码表示更简单:
def FIRST_ZBLOB(pg,pageno):
rdata = b''
d = zlib.decompressobj()
while True:
data = pg.read(pageno)
pre,nex = struct.unpack('>LL',data[8:16])
rdata += d.decompress(data[38:])
if nex == 4294967295:
break
else:
pageno = nex
return rdata缺点也很明显, 随便丢一个就都gg了, 而FIL_PAGE_TYPE_LOB_FIRST抽象了entry概念, 就…
测试
还是得测试才有说服力,代码已经更新了,故直接下载最新版ibd2sql即可测试:
wget https://github.com/ddcw/ibd2sql/archive/refs/heads/ibd2sql-v2.x.zip
unzip ibd2sql-v2.x.zip
cd ibd2sql-ibd2sql-v2.x
python3 main.py /data/mysql_3314/mysqldata/db1/t20260129_01.ibd --ddl --sql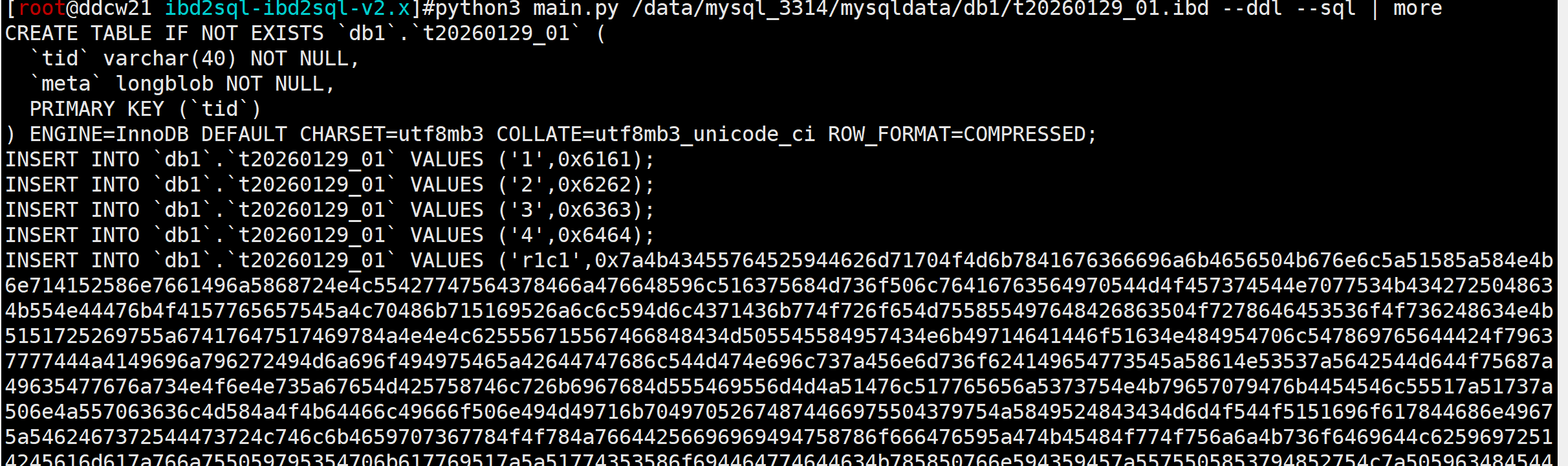
测试也是没得问题的. (小细节: 大字段中: lob显示为hex格式, text显示为字符形式, 也是根据mysql显示效果来的)
总结
虽然row_format=compressed使用得不多,但使用该格式就很可能有溢出页了. 简单总结下:
- row_format=compressed的元数据信息存储方式虽然复杂, 但我们只需要考虑不超过255字节的非空变长字段即可, 毕竟就它和结束标记符相同.
- row_format=compressed的溢出页比较简单, 直接按顺序解压即可. 各页之间是使用fil_header的NEXT_PAGE来关联的.
这篇文章补上了之前MySQL压缩行格式讲解里没涉及到的细节,把压缩元数据和溢出页的存储情况都讲清楚了,还用表格清晰列出了压缩行格式各组成部分的大小与作用,对想深入了解这块内容的人很有帮助,感谢分享,期待更多这类实用的技术细节讲解~