
大家好,我是 Ai 学习的老章
语音识别模型我之前都是用Belle-whisper-large-v3-zh,小巧、快速,但是方言支持和准确性差一点意思。最近智谱Z.AI 开源了 GLM-ASR-Nano-2512,一个专门针对方言识别优化的语音识别模型,支持粤语等多种方言,还能识别超小声音的低音量语音,这下子会议录音转文字的难题有解了!本文就详细介绍一下,介绍本地部署方法。
简介
GLM-ASR-Nano-2512 是智谱Z.AI 于2025年12月发布的开源语音识别模型,只有 1.5B 参数,体积不大但性能硬核,官方测评在多个基准测试中超越 OpenAI Whisper V3
核心亮点:
- 方言识别能力 🔥:除了标准普通话和英语,模型专门针对粤语和其他中国方言做了优化。做过会议纪要的朋友都知道,方言混着普通话说的场景,传统ASR直接崩溃。这个模型填补了这个空白。
- 低音量语音识别:这个feature我真的爱了。专门训练了"悄悄话"场景——开会时离麦克风远的人、电话录音声音弱的情况、嘈杂环境下压低声音说话……传统模型直接忽略的音频,它能捞回来。
- SOTA性能:在开源模型中,平均错误率只有4.10,在Wenet Meeting(真实会议场景)和Aishell-1(标准普通话)等中文基准测试中表现亮眼。
- 17种语言支持:WER≤20%的高可用性语言多达17种,覆盖面广。
下图是官方的benchmark结果,可以看到GLM-ASR-Nano在多个指标上全面领先:
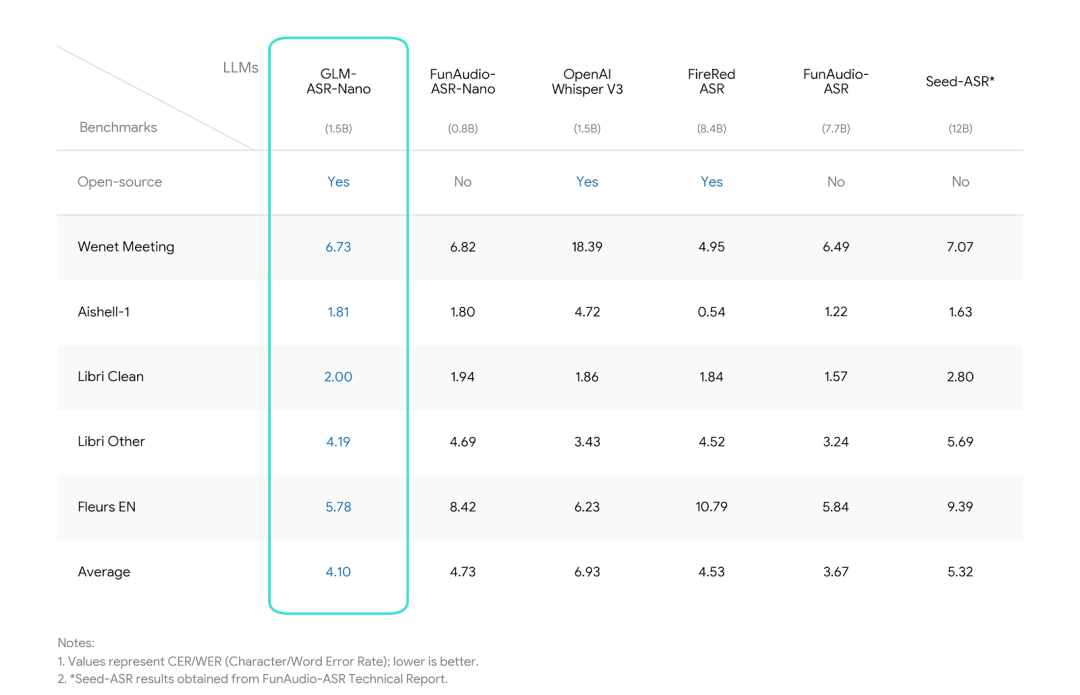
Benchmark results
支持的语言列表:

Supported Languages List
与 Whisper 的对比
问题来了,OpenAI 的 Whisper 也是开源的,还支持100多种语言,为什么要选 GLM-ASR?
选 GLM-ASR-Nano 的场景:
- ✅ 需要识别粤语、四川话等中国方言
- ✅ 会议录音中有很多低音量发言
- ✅ 需要本地部署,数据不出域
- ✅ 想针对特定领域(医疗、法律、金融)做微调
- ✅ 追求性价比,不想付API费用
选 Whisper 的场景:
- ✅ 需要100+语言的广泛覆盖
- ✅ 需要成熟的社区生态和文档
- ✅ 需要翻译功能(边转写边翻译)
- ✅ 处理全球各地口音的内容
说白了,如果你的业务场景是中文为主、涉及方言、或者有低音量语音识别需求,GLM-ASR-Nano 是更优解。如果是国际化场景、多语种混搭,Whisper 生态更成熟。
硬件要求
这个模型对硬件要求不算苛刻:
最低配置:
- GPU:8GB+ 显存(RTX 3060 起步)
- 内存:16GB
- 存储:5GB 模型权重
生产环境推荐:
- GPU:NVIDIA A100、V100 或同级别
- 内存:32GB+
- 存储:SSD以加速模型加载
官方说用 faster-whisper 优化后,在中端GPU(如降频的1080Ti)上可以实现比实时更快的解码速度。
安装
首先安装依赖:
pip install -r requirements.txt
sudo apt install ffmpeg
需要从源码安装 transformers 5.0.0:
pip install git+https://github.com/huggingface/transformers
使用
基础用法 – transformers 5.0.0
from transformers import AutoModel, AutoProcessor
import torch
device = "cuda"if torch.cuda.is_available() else"cpu"
repo_id = "zai-org/GLM-ASR-Nano-2512"
processor = AutoProcessor.from_pretrained(repo_id)
model = AutoModel.from_pretrained(repo_id, dtype=torch.bfloat16, device_map=device)
messages = [
{
"role": "user",
"content": [
{
"type": "audio",
"url": "example_zh.wav",
},
{"type": "text", "text": "Please transcribe this audio into text"},
],
}
]
inputs = processor.apply_chat_template(
messages, tokenize=True, add_generation_prompt=True, return_dict=True, return_tensors="pt"
)
inputs = inputs.to(device, dtype=torch.bfloat16)
outputs = model.generate(**inputs, max_new_tokens=128, do_sample=False)
print(processor.batch_decode(outputs[:, inputs.input_ids.shape[1]:], skip_special_tokens=True))
使用 vLLM 部署服务
我是用vllm起的,首先需要升级至vLLM 0.14.0稳定版
但是它对应的transformers是v4.57.6,需要单独升级它
从源码安装 🤗 Transformers 即可:
pip install git+https://github.com/huggingface/transformers
然后就是V5.0版本了 启动脚本
python -m vllm.entrypoints.openai.api_server --model /data/models/GLM-ASR-Nan0-2512
--trust-remote-code
--dtype bfloat16
--host 0.0.0.0
--port 8000
Python 调用:
from openai import OpenAI
# Modify with the actual server address
client = OpenAI(base_url="http://localhost:8000/v1", api_key="dummy")
# Transcribe audio file
with open("audio.mp3", "rb") as audio_file:
transcript = client.audio.transcriptions.create(
model="GLM-ASR-Nano-2512",
file=audio_file
)
print(transcript.text)
使用 SGLang 部署服务
SGLang 支持高吞吐量批处理,适合生产环境:
# 拉取开发版docker镜像
docker pull lmsysorg/sglang:dev
# 进入容器后运行
pip install git+https://github.com/huggingface/transformers
python3 -m sglang.launch_server --model-path zai-org/GLM-ASR-Nano-2512 --served-model-name glm-asr --host 0.0.0.0 --port 8000
然后用 OpenAI 兼容的 API 调用:
from openai import OpenAI
openai_api_key = "EMPTY"
openai_api_base = "http://127.0.0.1:8000/v1"
client = OpenAI(api_key=openai_api_key, base_url=openai_api_base)
response = client.chat.completions.create(
model="glm-asr",
messages=[
{
"role": "user",
"content": [
{
"type": "audio_url",
"audio_url": {"url": "example_zh.wav"}
},
{
"type": "text",
"text": "Please transcribe this audio into text"
},
]
}
],
max_tokens=1024,
)
print(response.choices[0].message.content.strip())
批量推理
如果需要处理多个音频文件,可以一次性传入:
from transformers import GlmAsrForConditionalGeneration, AutoProcessor
processor = AutoProcessor.from_pretrained("zai-org/GLM-ASR-Nano-2512")
model = GlmAsrForConditionalGeneration.from_pretrained("zai-org/GLM-ASR-Nano-2512", dtype="auto", device_map="auto")
inputs = processor.apply_transcription_request([
"audio1.mp3",
"audio2.mp3",
])
inputs = inputs.to(model.device, dtype=model.dtype)
outputs = model.generate(**inputs, do_sample=False, max_new_tokens=500)
decoded_outputs = processor.batch_decode(outputs[:, inputs.input_ids.shape[1]:], skip_special_tokens=True)
print(decoded_outputs)
应用场景
根据官方和社区反馈,这个模型特别适合以下场景:
- 企业会议转写:支持方言混杂、远距离发言者识别
- 客服中心:不同地区客户口音各异,方言识别是刚需
- 医疗记录:医生口述病历,往往声音轻、语速快
- 媒体与广播:地方电视台、网络主播内容转写
- 边缘设备部署:1.5B参数,可以在消费级GPU上运行
下载地址
平台 |
链接 |
|---|---|
🤗 Hugging Face |
https://huggingface.co/zai-org/GLM-ASR-Nano-2512 |
🤖 ModelScope |
https://modelscope.cn/models/ZhipuAI/GLM-ASR-Nano-2512 |
GitHub |
https://github.com/zai-org/GLM-ASR |
⚠️ 注意:如果你在2025年12月27日之前下载过模型,需要重新拉取最新版本,因为模型权重格式已更新以兼容 transformers 和 SGLang。
总结
GLM-ASR-Nano-2512 是目前开源ASR模型中,针对中文方言识别和低音量语音处理最优秀的选择。1.5B的参数量意味着更低的部署成本,对于企业级私有化部署来说,这是个实打实的利好。
优点:
- 🔥 粤语等方言识别能力强
- 🔥 低音量语音处理效果好
- 🔥 开源免费,可本地部署和微调
- 🔥 支持 transformers 5.x、vLLM、SGLang 等主流推理框架
局限:
- 语言覆盖不如 Whisper 广(100+ vs 17种)
- 社区生态还在建设中
- transformers 需要从源码安装(5.0.0)
如果你正在做语音识别相关的项目,特别是面向中文用户、涉及方言场景的,强烈建议试一试这个模型。