
导读
前段时间遇到某数据库进程状态为: T (disk sleeping) , 即在处于一个不可中断的IO等待中, 此时数据库无法连接(包括socket), 估计是cgroup达到限制了, 干掉同组的其它进程后,资源释放, 状态变成了T (stopped),这个状态和ctrl+z类似, 于是发送"SIGCONT"信号量之后变成了Sleep.
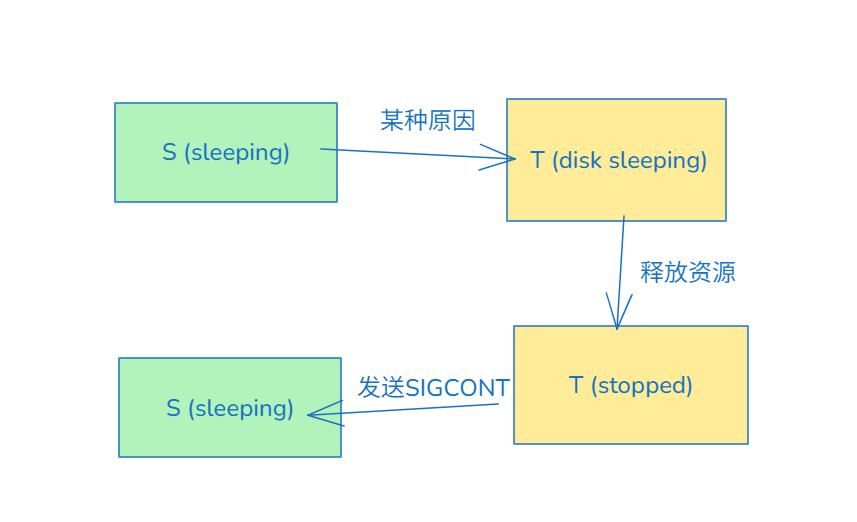
这就让人好奇mysql支持哪些信号量,进程状态又能在哪些状态之间变化?
能力有限, 简单分析分析
信号量
我们查询官网(https://dev.mysql.com/doc/refman/8.0/en/unix-signal-response.html)发现如下:
- SIGTERM 和shutdown命令效果一样
- SIGHUP 就是flush语句的效果
- SIGUSR1 就是flush error log, slow log,general query log
- SIGINT (Ctrl+c) 通常被忽略(除非
--gdb)
有丢丢简单啊, 本着习惯,我们看看源码sql/mysqld.cc, 发现还有SIGQUIT,SIGUSR2. 而且有各信号量更具体的信息. 再次整理得到 mysqld 信号量处理
信号量 |
作用 |
|---|---|
SIGTERM/SIGQUIT |
正常停库 |
SIGHUP |
REFRESH_LOG,REFRESH_TABLES,REFRESH_FAST,REFRESH_GRANT,REFRESH_THREADS,REFRESH_HOSTS |
SIGUSR1 |
REFRESH_ERROR_LOG,REFRESH_GENERAL_LOG,REFRESH_SLOW_LOG |
SIGUSR2 |
重启 |
SIGINT |
忽略 |
mysql怎么实现重启的?
SIGUSR2信号量能重启mysqld, 这个重启就比较"神奇", 进程还能自己重启自己? 怎么实现的?
其实只是退出的时候设置下进程的退出状态码而已,启动还是由mysqld_safe/system等其它线程来实现.
/**
Exit code used by mysqld_exit, my_thread_exit function which allows
for external programs like systemd, mysqld_safe to restart mysqld
server. The exit code 16 is chosen so it is safe as InnoDB code
exit directly with values like 3.
*/
constexpr const int MYSQLD_RESTART_EXIT{16};既然mysqld_safe能根据退出状态码重启mysqld, 我们就来验证验证:
ps -ef | grep mysqld
kill -SIGUSR2 35425
ps -ef | grep mysqld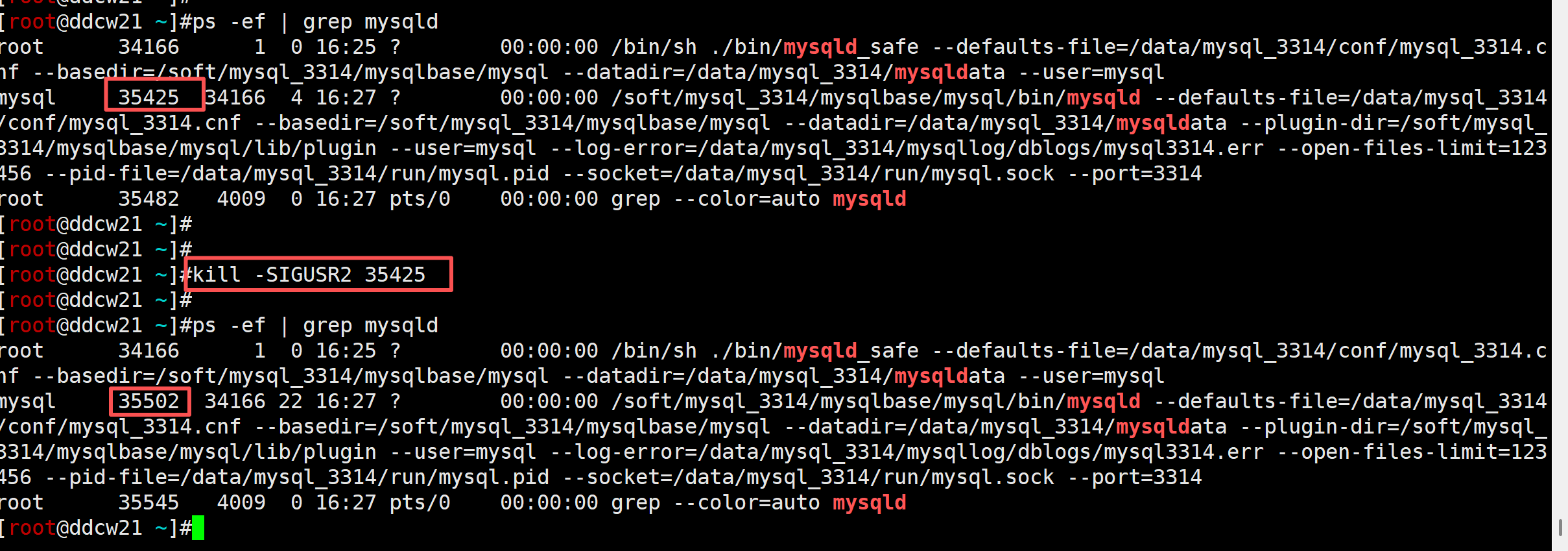
还真就重启了, 我们来看下mysqld日志呢:
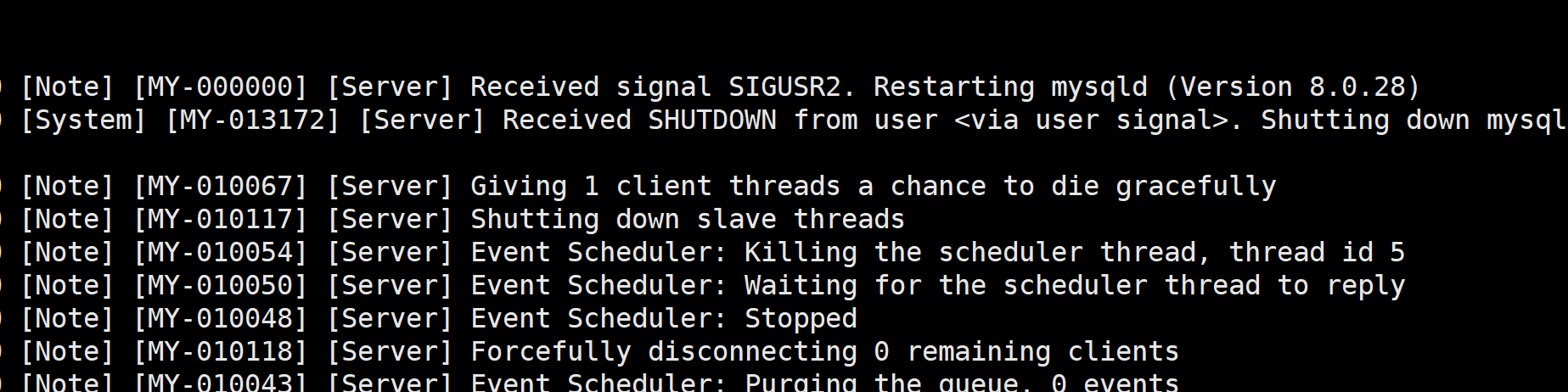
再看看mysqld_safe的输出:

我们再简单看看mysqld_safe脚本的逻辑:
while true
do
start_time=`date +%M%S`
eval_log_error "$cmd"
if [ $? -eq 16 ] ; then
dont_restart_mysqld=false
echo "Restarting mysqld..."
else
dont_restart_mysqld=true
fi
....
done确实做了退出状态码的判断的, 如果退出状态码是16,则设置dont_restart_mysqld=false, 后面如果就是'if dont_restart_mysqld; do something… break; 然后才是重启'
该说不说这变量名字dont容易看出do….
所以以后即使没有写重启脚本, 也能使用kill -SIGUSR2 mysqld_pid来实现重启mysql了, 还是比较方便.
如果对信号量感兴趣,可以看下https://www.man7.org/linux/man-pages/man7/signal.7.html, 太TM多了
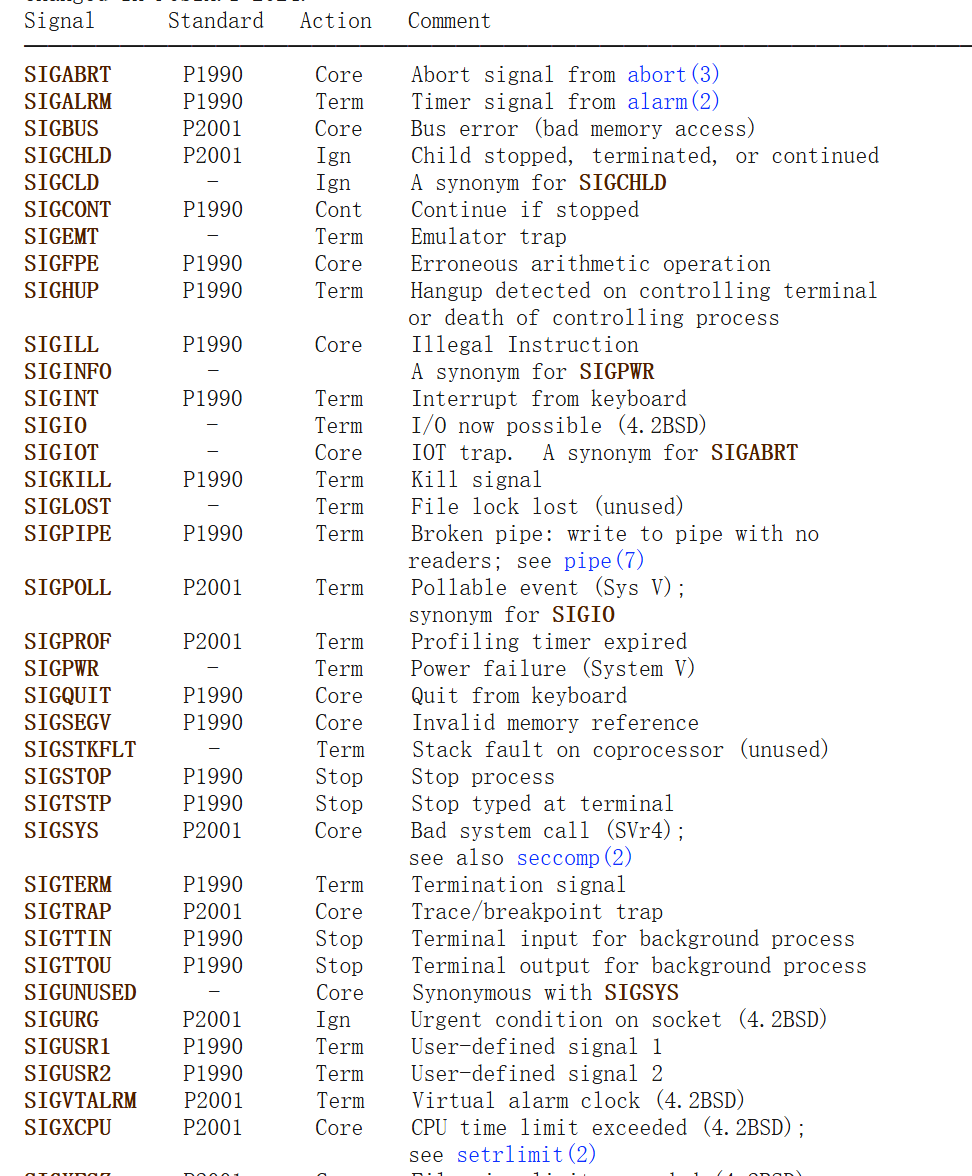
其实客户端mysql也有信号量处理的,虽然就一个SIGINT(ctrl+c),但还是挺好用的,mariadb之类的就没得….
写脚本的时候可能也需要处理信号量,这里给下shell/python的信号量捕获方法:
# shell
RUN_FUNC(){
echo "Ctrl+c"
}
trap 'RUN_FUNC' SIGINT
# python
import signal
def RUN_FUNC(sig,frame):
print("Ctrl+c")
signal.signal(signal.SIGUSR1, RUN_FUNC)进程状态
然后我们来瞅瞅进程状态, 进程状态一共有6种:
|进程状态|描述|
|-|-|-|
|D|uninterruptible sleep, 不可中断, 就是文章开头遇到的那种|
|R|running, 就是正在运行,通常只有少部分是这个状态,除非你cpu贼多,进程也贼多|
|S|sleeping 通常多数进程都是Sleeping的,等待唤醒. show processlist看到的sleep估计也是这么设计的|\
|T|stopped by job control signal 就是文章开头的第二种状态|
|t|stopped by debugger during trace 使用gdb之类调试的时候的状态|
|Z|zombie 僵尸状态, 被僵尸感染了,变异了,被豌豆射手克制,之前cf朝歌遗迹绳子小僵尸排队找救赎天使打针-_-|
既然已经知道了这几种状态, 那就来模拟模拟吧! 主要使用cgroup(control group based traffic control filter)来限制资源, 那就先看看cgroup怎么使用吧:
我这里是centos 7.9环境,是支持crgoup的, 虽然是v1
# 创建cgroup名字, 叫test_cgroup, 其实就是一个目录,然后往目录里面写东西,这就是vfs的方便之处....
mkdir /sys/fs/cgroup/memory/test_cgroup
# 限制使用20MB内存
echo "20971520" > /sys/fs/cgroup/memory/test_cgroup/memory.limit_in_bytes
# 把要限制的进程pid加进去
echo "16961" >> /sys/fs/cgroup/memory/test_cgroup/cgroup.procsmemory.limit_in_bytes是限制内存的,但超过内存之后会使用swap(如果有swap的话).
memory.memsw.limit_in_byte 是限制内存和swap使用的, 默认是9223372036854771712, 就是不限制swap大小.
所以要到达内存限制的话, 可以关闭swap (swapoff -a)

超过内存的进程会被kill

D 不可中断
有些状态是不可中断的, 比如IO, 那我们就使用cgroup来限制进程的IO
# 创建IO相关的cgroup目录
mkdir /sys/fs/cgroup/blkio/test_cgroup
# 设置指定设备的IO大小
# lsblk看到的MAJ:MIN 就是这里的253:0 1就是限制的值,单位是byte. 我这里限制的是带宽,还可以限制iops
echo "253:0 1" > /sys/fs/cgroup/blkio/test_cgroup/blkio.throttle.read_bps_device
echo "253:0 1" > /sys/fs/cgroup/blkio/test_cgroup/blkio.throttle.write_bps_device
# 把要限制的进程pid加入进去
echo `pidof mysqld` >> /sys/fs/cgroup/blkio/test_cgroup/cgroup.procs
# 线程也是可以加进来的,看自己需求了.
ps -T -p `pidof mysqld` | awk '{if ($2!="SPID") print $2}' | xargs -t -i echo {} >/sys/fs/cgroup/blkio/test_cgroup/tasks 2>/dev/null
# 取消限制
echo "253:0 0" > /sys/fs/cgroup/blkio/test_cgroup/blkio.throttle.read_bps_device
echo "253:0 0" > /sys/fs/cgroup/blkio/test_cgroup/blkio.throttle.write_bps_device
echo "253:0 0" > /sys/fs/cgroup/blkio/test_cgroup/blkio.throttle.read_iops_device 
然后就是触发主进程的IO操作,我知道的主进程的IO操作就只有shutdown… 正好我们用信号量来做.
head /proc/`pidof mysqld`/status
kill -15 `pidof mysqld`
head /proc/`pidof mysqld`/status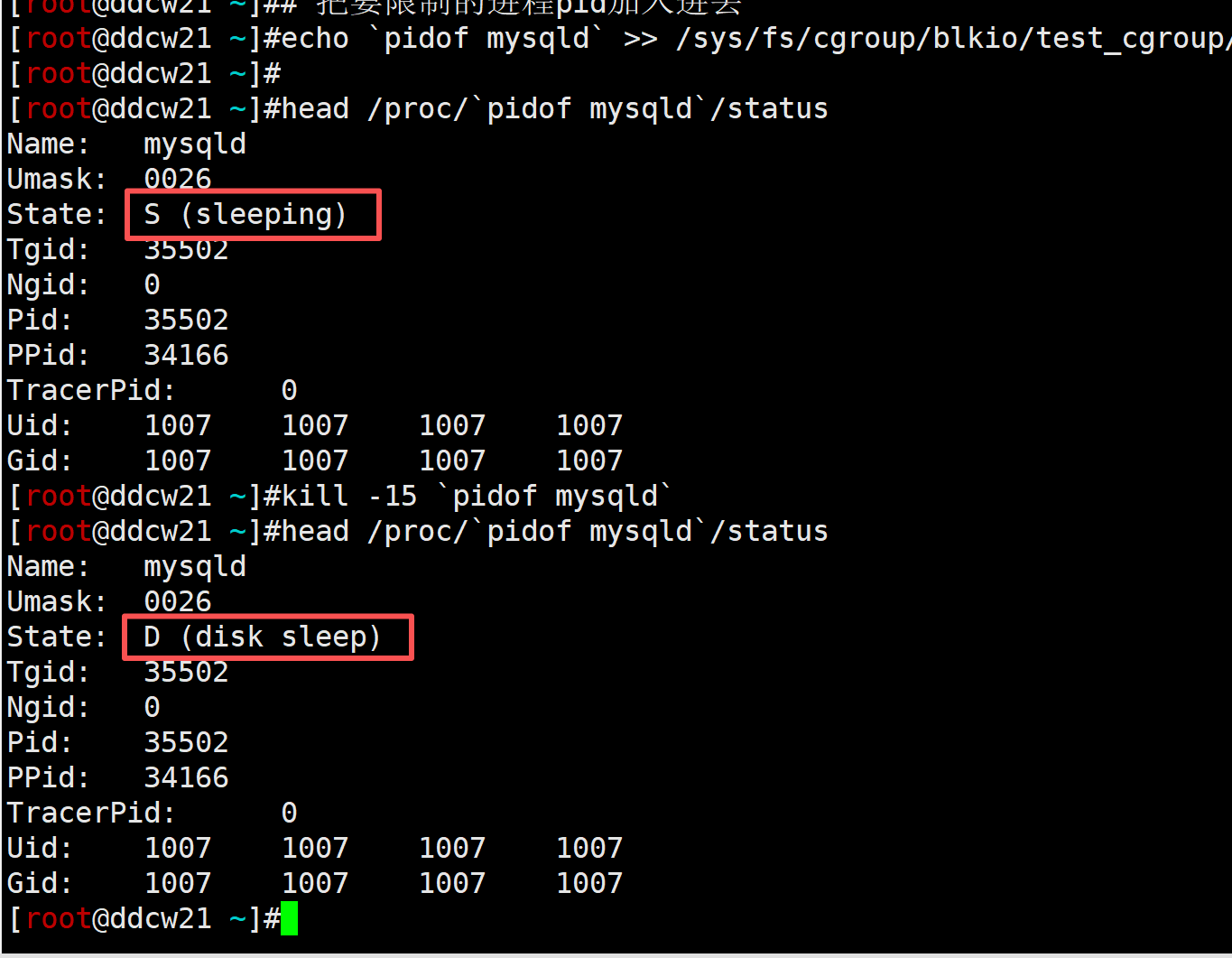
确实从S (sleeping)变成了D (disk sleep), 蒸蚌!
T (stopped)
R和S常见,就不看了, T其实就是ctrl+z
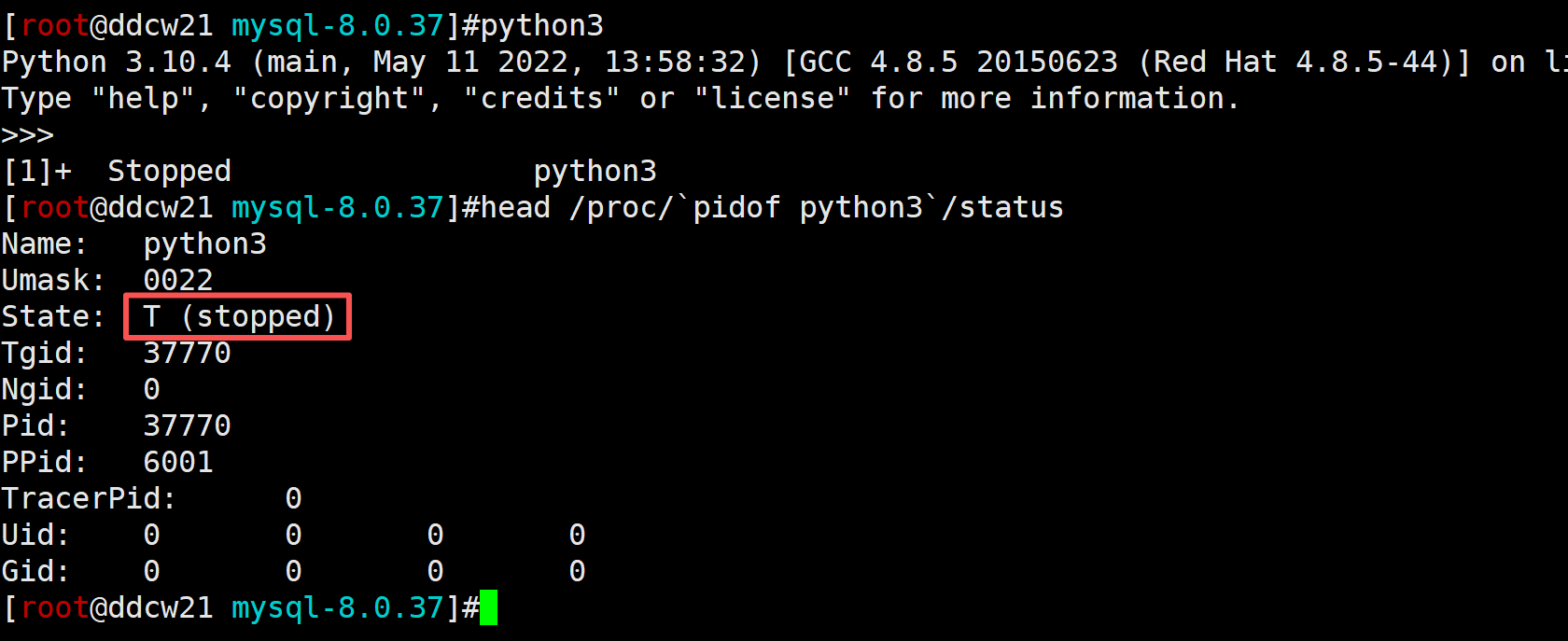
是不是很简单, 那mysqld怎么进入T状态呢?
当然是使用信号量啊, 直接
kill -SIGSTOP `pidof mysqld`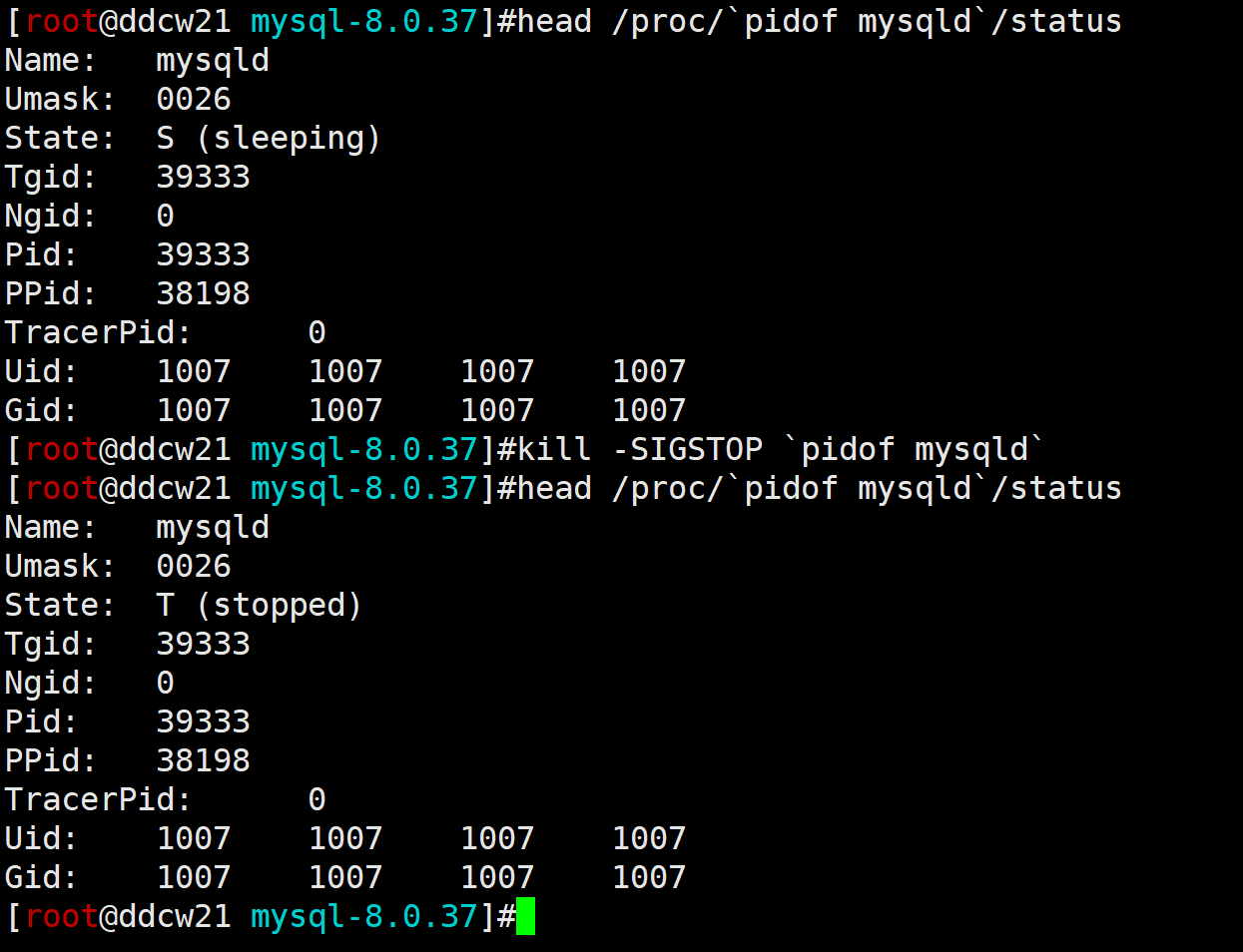
但之前测试的时候,误打误撞从D进入了T. 原因不明,大概操作如下:
# 配置线程级别的io限制
mkdir -p /sys/fs/cgroup/blkio/test_cgroup
echo "253:0 1" > /sys/fs/cgroup/blkio/test_cgroup/blkio.throttle.read_bps_device
echo "253:0 1" > /sys/fs/cgroup/blkio/test_cgroup/blkio.throttle.write_bps_device
ps -T -p `pidof mysqld` | awk '{if ($2!="SPID") print $2}' | xargs -t -i echo {} >/sys/fs/cgroup/blkio/test_cgroup/tasks 2>/dev/null
# 然后server执行sql(有IO就行)
mysql -h127.0.0.1 -P3314 -p123456 -e "show databases;"
# 此时应该能看到线程处于D状态
for i in /proc/`pidof mysqld`/task/*; do grep State ${i}/status;done;
# 然后等了一段时间,忘记多久了,但肯定不止10分钟.放开资源限制:
echo "253:0 0" > /sys/fs/cgroup/blkio/test_cgroup/blkio.throttle.read_bps_device
echo "253:0 0" > /sys/fs/cgroup/blkio/test_cgroup/blkio.throttle.write_bps_device
# 再观察主进程状态, 发现就变成了T (stopped)
head /proc/`pidof mysqld`/status总结
mysql信号量处理:
- SIGTERM/SIGQUIT就是停库
- SIGUSR2就是重启,
- SIGHUB就是FLUSH全部,
- SIGUSR1就是FLUSH日志.
mysql进程通常处于Sleep/Running状态,
- 如果出现了较长的D则表示IO等可能有问题.
- 如果是T的话,就是被人暂停了(SIGSTOP),使用SIGCONT就能恢复.
- 如果是t的话,就是有人在使用gdb调试.
文章开头的案例并没有完整的复现出来, 但基本上可以确定是cgroup配置不合理,或者资源争抢太离谱之类的.
参考:
https://dev.mysql.com/doc/refman/8.0/en/unix-signal-response.html
https://www.kernel.org/doc/html/latest/admin-guide/cgroup-v1/blkio-controller.html
这篇文章从实际遇到的MySQL进程T状态问题切入,还整理了官网里几个常用信号量的作用,把专业问题讲得很接地气。之前我对数据库进程状态和信号量的认知很模糊,看完不仅明白遇到类似IO等待导致的无法连接该怎么处理,也理清了不同信号量的实际用途,感谢作者的干货分享!