
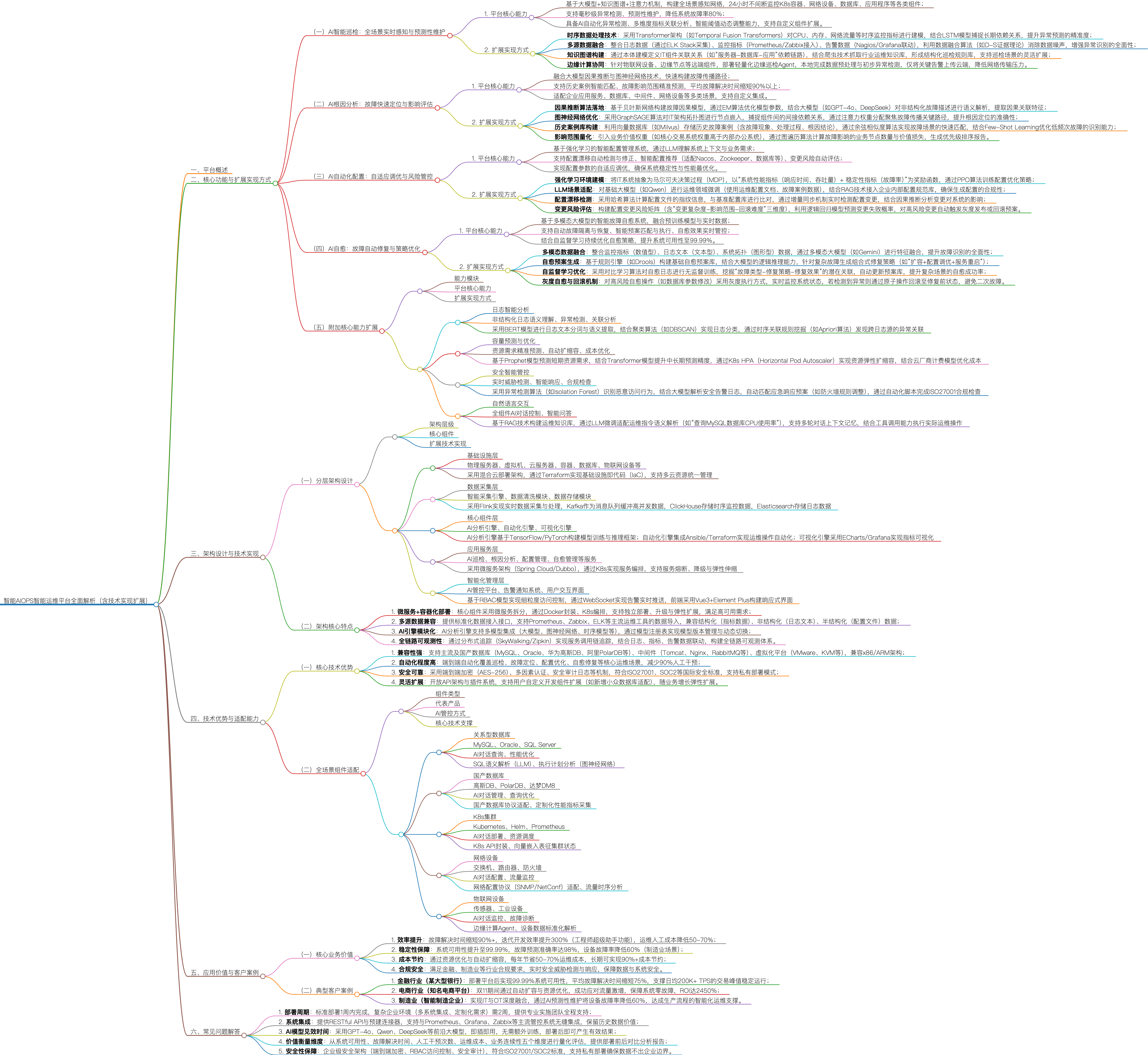
一、运维痛点催生的技术革新:AIOPS核心定位与价值
做运维的都清楚,传统运维早已跟不上企业IT架构的复杂度,动辄上千台服务器、多集群K8s部署、混合云架构下的异构组件,再加上业务迭代速度越来越快,“告警风暴”“排查难”“配置乱”“半夜救火”成了常态。更头疼的是,故障发生后往往要跨团队扯皮,从应用、数据库、中间件到网络逐一排查,等找到根因,业务已经损失惨重。
新一代AIOPS(智能运维)的核心,就是用“大模型+多技术融合”破解这些痛点。它不是传统运维工具的简单叠加,而是一套“数据采集-智能分析-自动化执行”的全链路闭环解决方案,覆盖从基础设施到上层应用的全层级IT组件。核心目标很明确:把系统可用性拉满到99.99%、平均故障解决时间(MTTR)缩短90%以上、运维人工成本降低50-70%,这不是空谈,而是经过金融、电商、制造等多行业验证的实际效果。
二、核心功能深析:从技术原理到落地细节
AI智能巡检:从“被动告警”到“主动预言”的质变
传统巡检要么靠人工盯仪表盘,要么靠固定阈值告警,最大问题是“滞后性”和“误报率高”,内存泄漏初期指标正常,等告警时系统已经濒临崩溃;非核心系统的小波动触发大量告警,反而掩盖了关键问题。新一代AI巡检的突破,就是实现“预测性维护”,把故障率直接降低80%。
从技术层面看,时序数据建模是核心支撑,这里优先采用Temporal Fusion Transformers(时序融合Transformer)而非传统LSTM,原因很简单:IT监控指标(CPU、内存、网络流量)不仅有长期趋势(比如工作日vs周末的负载差异),还有短期波动(比如突发的用户请求峰值),LSTM在捕捉“长期+短期”双重特征时容易顾此失彼,而Temporal Fusion Transformers能通过多尺度注意力机制同时兼顾两者,提前3-7天精准预测资源瓶颈(比如“周五晚8点核心服务CPU使用率将突破90%”)。落地时还要注意“业务上下文对齐”,比如电商平台要把巡检模型和促销活动日历联动,活动前自动调严阈值,避免因流量激增误判为异常。
多源数据融合是打通数据孤岛的关键,单一指标的异常没意义,比如“数据库连接数突增”,可能是正常的业务高峰,也可能是异常请求。所以必须整合日志(通过ELK Stack采集)、监控指标(Prometheus/Zabbix接入)、告警数据(Nagios/Grafana联动),再用D-S证据理论消除数据噪声(比如过滤掉测试环境的无效日志),建立“指标-日志-拓扑”的关联关系。举个实际场景:巡检系统发现某应用响应时间变长,同时关联到数据库慢查询日志增多、服务器IO使用率飙升,就能直接定位到“数据库索引失效”,而非孤立看某一个指标。
知识图谱与边缘协同则解决了复杂场景适配问题,通过本体建模构建IT组件依赖图谱(比如“负载均衡→Web服务器→缓存→数据库”),让巡检能理解“某一个组件异常会影响哪些下游业务”。对于物联网设备、边缘节点等远端组件,不能把所有数据都传到云端(占带宽且延迟高),所以要部署轻量化边缘Agent,本地完成数据预处理和初步异常检测,只把关键告警(比如设备离线、硬件故障)上传云端。
AI根因分析:10秒定位故障,告别跨团队扯皮
故障发生后,最值钱的是“时间”,金融行业每秒交易损失可能达数万,电商大促时一秒卡顿就可能流失上千用户。传统根因分析靠“经验+拉群排查”,跨团队扯皮半小时很正常,而新一代AI根因分析能直接缩短90%以上的故障解决时间。
其核心技术逻辑是“因果推断+图神经网络”,拒绝把“相关性”当“因果性”。很多初级AIOPS会犯一个错:发现“告警时CPU使用率高”,就判定是CPU问题,其实可能是内存泄漏导致的CPU代偿性飙升。新一代方案用贝叶斯网络构建故障因果模型,通过EM算法优化参数,结合大模型(GPT-4o、DeepSeek)解析非结构化故障描述(比如日志里的错误堆栈、运维的口头描述),提取“因-果”关联特征。再结合GraphSAGE算法对IT拓扑图做节点嵌入,捕捉组件间的间接依赖关系(比如“前端页面加载慢”,根因可能是“远端CDN节点故障”),通过注意力权重分配聚焦故障传播关键路径,避免“头痛医头、脚痛医脚”。
向量数据库与Few-Shot Learning则弥补了“经验缺口”,老运维的价值在于“见过更多故障”,但单个人的经验有限。新一代方案用Milvus等向量数据库存储历史故障案例(含故障现象、处理过程、根因结论),通过余弦相似度算法快速匹配相似场景,比如遇到“Redis集群脑裂”,直接调出历史处理方案。对于低频次故障(比如一年只发生1次的硬件兼容性问题),用Few-Shot Learning(少样本学习),只需要几个案例就能让模型学会识别,大幅提升少见故障的处理能力。
影响范围量化则解决了“优先级排序”问题,不是所有故障都要立刻处理,核心是“分清轻重缓急”。方案里引入“业务价值权重”(比如核心交易系统权重10,内部办公系统权重1),通过图遍历算法计算故障影响的业务节点数量和价值损失,生成优先级报告,比如“影响日均200K+TPS的支付系统”会排在最前面,优先调配资源解决。
AI自动化配置:自适应调优,杜绝“配置漂移”坑
配置管理是运维的“隐形炸弹”,很多故障都是“配置改乱了”导致的:手动改了数据库连接池参数忘了同步,导致集群不一致;升级中间件后配置没适配,引发性能雪崩。AI自动化配置的核心是“自适应+防风险”,让配置始终处于最优且安全的状态。
强化学习建模是实现自适应调优的关键,把IT系统抽象成马尔可夫决策过程(MDP),以“响应时间+吞吐量+故障率”为奖励函数,通过PPO算法训练配置优化策略。比如Tomcat的线程池参数,人工凭经验可能设为“最大线程数200”,但AI会根据实时业务流量(比如高峰时调到500,低谷时降到50)动态调整,平衡性能和资源消耗。落地时要注意“安全边界”,给模型设置参数阈值(比如数据库连接数最大不能超过1000),避免模型试错时触发系统崩溃。
LLM与RAG技术则让配置“懂业务”,不用写复杂脚本,运维直接说“把订单服务的响应时间优化到500ms以内”,LLM就能听懂。关键是要对基础大模型(比如Qwen)做运维领域微调,用企业内部的配置文档、故障案例训练,再结合RAG技术接入公司的配置规范库(比如“金融行业数据库必须开启加密”),确保生成的配置合规。
配置漂移检测与灰度发布则构建了风险防护网,用哈希算法计算配置文件的“指纹”,和基准配置库实时比对,一旦发现变更(比如有人手动改了参数),立刻触发告警并分析影响。对于高风险配置变更(比如修改数据库内核参数),自动触发灰度发布,先在1台测试机上执行,监控10分钟无异常再批量推广,出问题能通过原子操作一键回滚。
AI自愈:从“手动修复”到“自动止血”,可用性拉满99.99%
自愈不是“简单重启服务”(那是入门级操作),而是“智能判断+精准操作+预防复发”的闭环,比如遇到“数据库死锁”,不仅要自动解锁,还要调整锁超时参数,避免再次发生。这也是系统可用性能提升到99.99%的关键(意味着每年 downtime 不超过52分钟)。
多模态大模型是实现智能判断的核心,故障判断不能只看监控指标(数值型),还要结合日志文本(比如错误堆栈)、系统拓扑图(图形型)。多模态大模型(比如Gemini)能融合这些数据,全面判断故障类型,比如同样是“服务宕机”,能区分是“内存溢出”(需要重启+调优参数)还是“硬件故障”(需要自动切换到备用节点)。
规则引擎与组合式策略则应对了复杂故障场景,基于Drools等规则引擎构建基础自愈预案库(比如“Nginx宕机→自动重启”),但复杂故障需要组合策略,比如“订单支付超时”,可能需要“切流量到备用集群+扩容缓存+修复数据库索引”三步联动,这就需要大模型的逻辑推理能力生成组合方案。
自监督学习与灰度自愈则让系统“越用越聪明,越用越安全”,用对比学习算法对自愈日志做无监督训练,挖掘“故障类型-修复策略-修复效果”的潜在关联,比如发现“某类缓存击穿用‘扩容+预热’比‘重启’效果更好”,就自动更新预案库。对于高风险自愈操作(比如修改核心配置),同样采用灰度模式,实时监控系统状态,避免二次故障。
附加核心能力补全运维全场景
除了四大核心功能,新一代AIOPS还覆盖了运维全场景的附加能力,形成完整支撑体系:
|
能力模块 |
核心价值 |
深度技术细节 |
|---|---|---|
|
日志智能分析 |
从海量日志里快速找问题 |
用BERT做日志语义提取(比如把“OOM”翻译成“内存溢出”),DBSCAN聚类分类日志(比如把同一类错误归为一组),Apriori算法挖掘跨日志源关联(比如“应用报错和数据库慢查询同时发生”) |
|
容量预测与优化 |
避免“资源浪费”和“资源不足” |
短期预测用Prophet(适合有周期性的流量,比如电商大促),中长期用Transformer(适合趋势复杂的场景);结合K8s HPA自动扩缩容,再对接云厂商计费模型(比如阿里云按量付费),优化成本 |
|
安全智能管控 |
实时防攻击,满足合规 |
用Isolation Forest算法识别异常访问(比如高频恶意扫描),大模型解析安全告警日志(比如把IDS告警翻译成“SQL注入攻击”),自动匹配预案(比如调整防火墙规则);自动化脚本完成ISO27001合规检查(比如定期检查日志留存时间) |
|
自然语言交互 |
运维“说话办事”,不用记命令 |
基于RAG构建企业专属运维知识库,LLM微调后能理解口语化指令(比如“查一下MySQL的CPU使用率”),支持多轮对话(比如接着问“是哪台机器高”),还能调用工具执行操作(比如“重启那台机器的Nginx”) |
三、架构设计:五层架构+微服务,既稳定又能扩
很多技术文档把架构写得云里雾里,其实新一代AIOPS的架构核心是“分层解耦”,方便后续扩展(比如新增国产数据库适配)和维护(比如AI引擎升级不影响采集功能),用大白话拆成五层,每层都有明确的设计考量:
|
架构层级 |
核心组件 |
技术实现细节 |
设计考量(为什么这么做) |
|---|---|---|---|
|
基础设施层 |
物理机、虚拟机、云服务器、容器、数据库、物联网设备 |
混合云部署,Terraform实现IaC(基础设施即代码) |
企业IT环境大多是混合云(既有私有云又有公有云),IaC能实现多云资源统一管理,避免手动部署出错 |
|
数据采集层 |
智能采集引擎、数据清洗、Kafka、ClickHouse、Elasticsearch |
Flink实时采集,Kafka缓冲高并发数据,ClickHouse存时序指标,Elasticsearch存日志 |
Flink比Spark更适合实时处理(运维要的是“当下的问题”,不是“昨天的报表”);ClickHouse写快查快,适合时序数据;Elasticsearch擅长全文检索,适合日志分析 |
|
核心组件层 |
AI分析引擎、自动化引擎、可视化引擎 |
AI引擎基于TensorFlow/PyTorch,支持多模型集成;自动化引擎集成Ansible/Terraform;可视化用ECharts/Grafana |
AI引擎模块化(大模型、图神经网络等独立部署),方便动态切换模型;Ansible擅长配置管理,Terraform擅长基础设施操作,互补使用;Grafana是运维标配,兼容性强 |
|
应用服务层 |
巡检、根因分析、配置管理、自愈等服务 |
微服务架构(Spring Cloud/Dubbo),K8s编排 |
微服务能独立升级(比如优化根因分析算法,不用停整个平台);K8s能实现弹性扩缩容,应对高并发(比如大促时巡检请求激增) |
|
交互层 |
AI管控平台、Web界面、自然语言对话、API接口 |
RBAC权限控制,WebSocket实时推送告警,Vue3+Element Plus前端 |
RBAC支持细粒度权限(比如开发只能看日志,运维能执行自愈);WebSocket确保告警实时推送(不用刷新页面);Vue3响应式更好,适配不同设备 |
这套架构的核心特点的是“高可用、可扩展、易集成”:微服务+容器化部署确保单一组件故障不影响整体;多源数据兼容支持对接企业现有运维工具,不浪费历史投资;全链路可观测通过分布式追踪(SkyWalking/Zipkin)实现问题追溯,让运维能看清每一个环节的状态。
四、技术优势与适配能力:能落地、能扩展
核心技术优势(企业最关心的点)
- 兼容性拉满:异构环境也能装undefined支持主流及国产数据库(MySQL、Oracle、高斯DB、达梦DM8)、中间件(Tomcat、Nginx、RabbitMQ)、虚拟化平台(VMware、KVM),兼容x86/ARM架构,不管是老企业的物理机,还是新企业的云原生架构,都能无缝适配。
- 自动化程度高:省人就是省钱undefined端到端覆盖巡检、根因分析、配置优化、自愈,减少90%人工干预,比如原来需要10人团队维护的IT架构,现在2人就能搞定,每年省上百万人工成本。
- 安全合规:金融/制造都能用undefined端到端AES-256加密(数据传输和存储都安全)、RBAC权限控制、全链路安全审计日志,符合ISO27001、SOC2等标准;支持私有部署(数据不出企业边界),满足金融行业的严格合规要求。
- 灵活扩展:随业务一起成长undefined开放API和插件系统,比如企业有小众数据库,能自己开发适配插件;业务增长后,通过K8s弹性扩缩容,不用重构架构。
全场景组件适配(覆盖企业IT全栈)
|
组件类型 |
代表产品 |
AI管控方式 |
技术难点与解决方案 |
|---|---|---|---|
|
关系型数据库 |
MySQL、Oracle、SQL Server |
AI对话查询、性能优化、索引建议 |
难点:SQL语义解析精准度;方案:LLM微调+执行计划图分析 |
|
国产数据库 |
高斯DB、PolarDB、达梦DM8 |
AI对话管理、参数调优 |
难点:协议不统一;方案:定制化驱动+适配层开发 |
|
K8s集群 |
Kubernetes、Helm、Prometheus |
AI对话部署、资源调度、故障诊断 |
难点:动态拓扑感知;方案:K8s API实时采集+向量嵌入表征状态 |
|
网络设备 |
交换机、路由器、防火墙 |
AI对话配置、流量监控、攻击检测 |
难点:协议差异大;方案:SNMP/NetConf统一适配+流量时序分析 |
|
物联网设备 |
传感器、工业设备 |
AI对话监控、预测性维护 |
难点:边缘节点资源有限;方案:轻量化Agent+本地预处理 |
五、应用价值与案例:用数据说话
核心业务价值(企业老板最关心的回报)
- 效率提升:故障解决时间缩短90%+(比如从2小时缩到12分钟),工程师迭代效率提升300%(不用再花时间排查简单故障);
- 稳定性保障:系统可用性99.99%,故障预测准确率98%(大部分故障没发生就被掐灭),制造业设备故障率降低60%;
- 成本节约:资源优化+人工减少,每年省50-70%运维成本,长期(比如3年)可实现90%+成本节约(规模效应);
- 合规安全:满足金融、制造等行业合规要求,实时防御攻击,避免因安全问题导致的罚款和声誉损失。
典型案例(真实场景,有血有肉)
- 金融行业(某大型股份制银行)undefined痛点:核心交易系统日均200K+TPS,月初发薪日容易卡顿,故障排查要跨3个团队,平均耗时2小时,效果:部署后可用性达99.99%,故障解决时间缩短75%(从2小时缩到30分钟),发薪日再也没出现过卡顿,每年减少业务损失超千万。
- 电商行业(某头部直播电商平台)undefined痛点:双11峰值流量是日常的10倍,每次都要提前1周手动扩容,还经常出现“扩容不及时”导致的卡顿,效果:自动预测流量峰值并提前2小时扩容,双11零故障,ROI达2450%(投入1块钱,回报24.5块),运维团队从15人缩到3人。
- 制造业(某智能制造企业)undefined痛点:车间设备(传感器、机床)故障频发,停机1小时损失超5万,全靠老师傅经验判断故障,效果:通过AI预测性维护,设备故障率降低60%,每年减少停机损失超800万,实现IT(信息技术)与OT(运营技术)深度融合。
六、常见问题解答(运维/技术负责人常问的坑)
- 部署周期多久?复杂环境能搞定吗?undefined标准环境(比如纯云原生架构)1周内完成,复杂环境(多异构组件、定制化集成)2周内。有专业实施团队,会提前做POC(概念验证),确保适配再部署。
- 能和我们现有工具(比如Zabbix、Grafana)集成吗?undefined完全可以。提供RESTful API和预建连接器,能无缝对接Prometheus、Grafana、Zabbix、ELK等主流工具,历史数据不会浪费。
- AI模型需要我们自己训练吗?多久能见效?undefined不用。内置GPT-4o、Qwen、DeepSeek等前沿大模型,已经用海量运维数据预训练过,即插即用,部署后当天就能产生效果(比如异常检测、简单根因分析)。
- 怎么衡量落地价值?有没有量化指标?undefined从5个维度量化:系统可用性(部署前后对比)、故障解决时间(MTTR)、人工干预次数、运维成本(人工+资源)、业务连续性(故障导致的损失),会提供月度对比报告。
- 私有部署安全吗?数据会不会泄露?undefined安全。私有部署模式下,所有数据都存储在企业内部服务器,端到端加密,还有RBAC权限控制和安全审计日志,符合国家等保2.0、ISO27001等标准,数据绝对不会泄露。