
业界weakness
无法在训练之外实现泛化,模仿学习也是如此
解决方案Solution
融合视觉-语言模型,让模型具备推理能力,模块化指导规划和控制
参考模型:CLIP , SigLIP, and Llama 2 ;
以现有视觉 – 语言基础模型为核心构建块,训练可泛化至训练数据外的物体、场景与任务的机器人策略
VLA广泛应用的2个阻碍点
- 现有模型 均为闭源模式,其模型架构、训练流程及数据构成的可探究性极低;
- 架构:模型的网络结构、层间连接逻辑;
- 训练流程:训练超参数、优化器、训练步骤;
- 数据构成:预训练数据的类型、比例、标注方式;
- 现有研究尚未给出将视觉 – 语言模型(VLAs)部署并适配至新型机器人、新环境及新任务的最佳实践方案 —— 尤其是在通用硬件(如消费级显卡)上的部署适配方案
OpenVLA 模型由一个预训练的视觉条件语言模型骨干网络构成,该骨干网络可实现多粒度视觉特征的提取;模型在 Open-X 具身智能数据集 [1] 的 97 万条机器人操作轨迹构成的大规模多样化数据集上完成了微调 —— 这一数据集覆盖了丰富的机器人具身形态、任务类型与应用场景。
论文涉及的主要任务
- LoRA微调
- 量化
- 消费级显卡
推动近期 VLMs 发展的核心进展之一,是融合了预训练视觉编码器与预训练语言模型特征的模型架构;其依托计算机视觉和自然语言建模的技术进展构建,实现了高性能多模态模型的研发。
解释VLA是怎么回事?
VLM:A number of works have explored the use of VLMs for robotics, e.g., for visual state representations [12, 13], object detection [67], high-level planning [16], and for providing a feedback signal
VLA = VLM + predict action
VLM的技术实现
视觉语言模型(VLM)的经典训练流程(先单模态预训练,再跨模态对齐),也是自动驾驶多模态感知中 VLM 的核心训练逻辑 —— 先将视觉编码器(提取车道、车辆、交通标志等图像特征)、语言编码器(提取文本指令 / 场景描述等语言特征)分别预训练,再通过海量自动驾驶场景的视觉 – 语言配对数据做对齐,让模型能理解 “图像中的智驾场景” 与 “文字描述 / 人类指令” 的对应关系。
the use of a generic architecture, not custom-made for robot control, allows us to leverage the scalable infrastructure underlying modern VLM training [75–77] and scale to training billion-parameter policies with minimal code modiffcations,
这句话核心阐述了 “通用架构” 在机器人控制 VLM 策略训练中的核心价值,可拆解为两层关键逻辑:
- 摆脱专用架构的扩展性束缚传统机器人控制策略多为特定任务 / 硬件定制架构(比如为某款自动驾驶车型定制的视觉运动控制架构),代码和训练逻辑高度耦合,无法复用 VLM 领域已成熟的规模化训练体系;而通用架构不绑定具体机器人控制逻辑,能直接 “借力” VLM 的训练基础设施,避免从零搭建专属训练框架。
- 低成本实现大参数策略的规模化训练现代 VLM 训练已形成完整的可扩展基础设施(比如千亿参数 VLM 的分布式训练方案),通用架构可直接复用这些成熟能力;仅需少量代码修改(如适配机器人控制的输入:图像 + 文本指令;输出:车辆转向 / 机械臂抓取指令),就能将策略模型扩展到十亿参数级别,大幅降低研发成本和周期。
实际场景示例
以自动驾驶视觉运动控制为例:
- 若用为某款车型定制的专用架构,要训练十亿参数的控制策略,需重构整个训练框架、重新适配算力集群,耗时数月;
- 若用通用 VLM 架构(如 LLaVA/GPT-4V 的基础架构),可直接用 DeepSpeed 分布式训练框架(VLM 训练的成熟基础设施),仅修改输入输出的适配代码(约几百行),1-2 周就能启动十亿参数策略的训练。
总结
- 核心优势:通用架构打破了机器人控制专用架构的扩展性限制,可直接复用 VLM 领域成熟的规模化训练基础设施;
- 工程价值:仅需少量代码修改,就能低成本将机器人控制策略模型扩展至十亿参数级别;
- 核心逻辑:通过 “通用化架构设计” 衔接机器人控制任务与大模型训练体系,平衡了定制化需求与规模化训练效率。
模型架构
尽管早期研究探索了多种视觉 – 语言特征交叉注意力架构 [37–41],但新一代开源 VLMs [20,42–44] 已趋同于简洁的 patch-as-token 方法,该方法将预训练视觉 Transformer 的图像块特征视作 token,并投影至语言模型的输入空间。
本研究采用上述工具规模化开展 VLA 训练,具体以 Karamcheti 等人 [44] 的 VLMs 为预训练骨干网络;该模型基于多分辨率视觉特征训练,融合了 DINOv2 [25] 的低级空间信息与 SigLIP [9] 的高级语义信息,可有效提升视觉泛化能力。
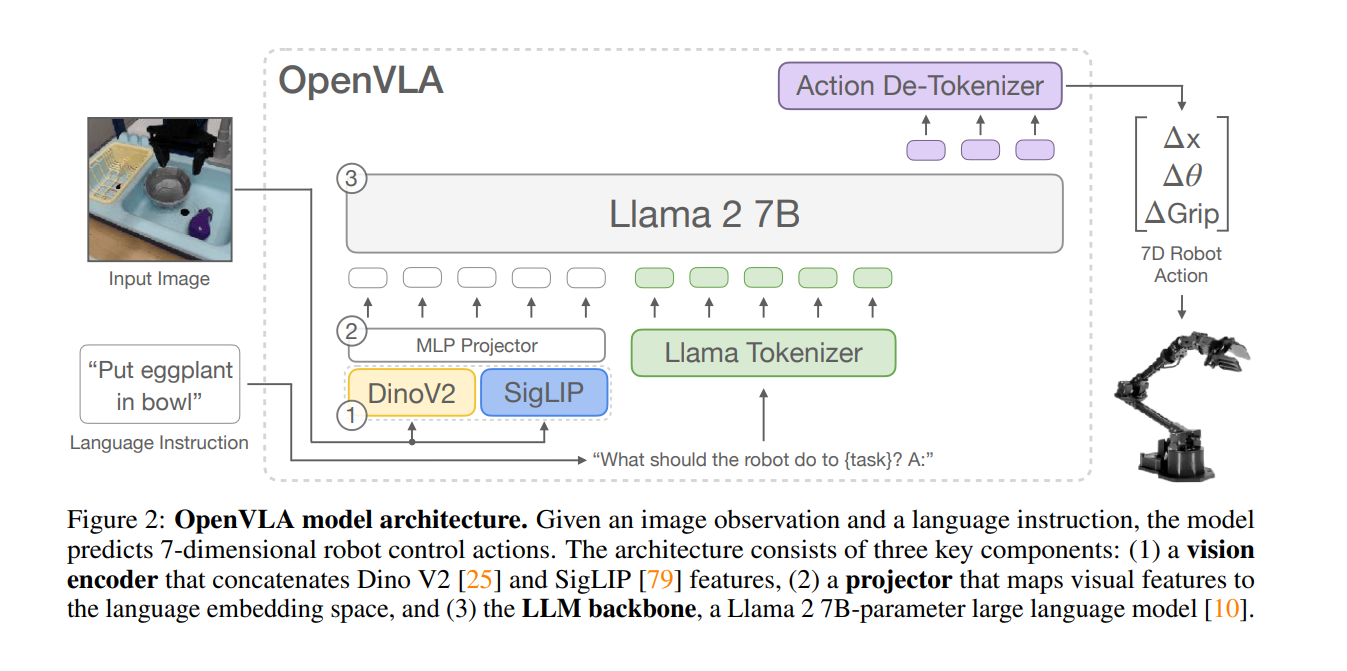
三模块的核心作用:该架构的核心是实现视觉与语言模态的特征对齐—— 视觉编码器做「图像特征提取」,投影层做「跨模态特征适配」,LLM 骨干网络做「语言特征融合与预测」,三者协同完成视觉 – 语言的联合建模。
end-to-end training(端到端训练):训练过程中三个模块的参数同步更新,无需分阶段训练,能让模型学习到更统一的跨模态表征,而非各模块独立的特征。
paired/interleaved vision-language data:
- 配对数据:图像与对应的文本描述(如 “猫在沙发上”+ 对应图片),是 VLMs 训练的基础数据;
- 交错数据:图像与文本混合的序列数据(如多图多文本的对话、图文问答语料),让模型适配更复杂的视觉 – 语言交互场景。
6 亿参数的视觉编码器、小型双层多层感知机投影层,以及70 亿参数的 Llama 2 语言模型骨干网络[10]。值得注意的是,Prismatic 采用双组件视觉编码器,由预训练的 SigLIP [79] 和 DinoV2 [25] 模型共同构成:输入的图像块会分别送入这两个编码器进行特征提取,生成的特征向量最终在通道维度完成拼接。与仅采用 CLIP [80] 或 SigLIP 这类更主流的视觉编码器的方案相比,研究已证实,融入 DinoV2 特征能有效提升模型的空间推理能力[44]—— 这一特性对于机器人控制任务而言尤为关键。
- 轻量架构的工程优势:Prismatic 的投影层仅为双层 MLP,视觉编码器 6 亿参数 + LLM 70 亿参数的组合,属于轻量型 VLMs,兼顾模型性能与推理速度,适配机器人端 / 边缘端的计算资源限制,是其能落地机器人控制的重要前提。
- 双视觉编码器的设计逻辑
- SigLIP:主打视觉 – 语言对齐,预训练于大规模图文配对数据,能精准理解图像的语义信息,适配 VLMs 的跨模态核心需求;
- DinoV2:主打纯视觉自监督表征,对物体的空间几何、局部细节、场景结构的表征能力极强,弥补了单一 SigLIP/CLIP 在纯空间信息理解上的不足。
- 为何适配机器人控制:机器人操控(如抓取、移动、避障)需要模型精准理解物体间的空间相对位置(如 “杯子在桌子左侧”)、物体的几何结构(如 “门把手的朝向”)、场景的空间布局(如 “从当前位置到椅子的路径”),而 DinoV2 带来的空间推理能力提升,恰好解决了传统 VLMs 在这类空间任务上的短板。
- 与单编码器方案的核心差异:仅用 CLIP/SigLIP 的编码器更侧重语义层面的图像理解,而 Prismatic 的双编码器实现了语义信息 + 空间信息的双重表征,让模型既能理解图像 “是什么”,也能精准判断 “在哪里 / 是什么结构”,更适配机器人的实际操控需求。
OpenVLM数据样本
三大基础模型的训练数据特征(未公开 + 超大规模)三者均采用互联网海量非结构化数据做预训练,且按自身任务特性做了数据类型区分:
- SigLIP(视觉 – 语言对齐模型):图文混合数据,适配跨模态特征匹配;
- DinoV2(纯视觉表征模型):纯图像数据,强化空间 / 视觉细节表征;
- Llama 2(纯语言模型):纯文本数据,夯实语言理解与生成能力。数万亿级 token 的预训练数据是模型具备强泛化能力的核心,也是三者不公开细节的主要原因(数据版权 / 隐私、模型技术壁垒)。
Prismatic 的微调策略:「大预训练 + 小微调」的经典范式Prismatic 未对三大基础模型做全量重训练,仅在其之上做轻量微调,核心优势有两点:
- 降低计算成本:微调仅用 100 万级样本,远低于预训练的万亿级,普通算力即可完成,适配后续机器人端的二次微调;
- 保留基础能力:复用三大模型经海量数据训练的核心表征能力(SigLIP 的跨模态对齐、DinoV2 的空间推理、Llama2 的语言能力),微调仅做特征融合与任务适配。
Prismatic 微调数据的核心特点:开源 + 图文 / 纯文本混合其采用的 LLaVA 1.5 数据混合集均来自开源数据集,相比三大基础模型的非公开数据,这一特性对机器人领域的二次开发尤为重要:研究人员 / 工程师可基于该开源微调数据复现 Prismatic 模型,还能在此基础上加入机器人专属数据集(如机械臂操控、场景导航的图文数据)做进一步微调,让模型更适配具体的机器人任务。
微调数据规模的合理性100 万个图文 + 纯文本样本是 VLMs跨模态微调的黄金规模:既足够让投影层完成视觉 / 语言特征的精准对齐,又不会因数据量过大导致模型过拟合,同时保证了微调的效率,符合 Prismatic 轻量型 VLMs 的定位(适配机器人端有限的计算资源)。
Infrastructure for Training and Inference
本段是 OpenVLA工程化部署的核心细节,所有设计均围绕 「让大模型能在普通硬件上跑、能实时控制机器人、能低成本落地」 展开,每一个指标和方案都对应机器人实际应用的痛点,关键逻辑如下:
-
训练算力配置:大批次 + 高算力集群,保证模型收敛与性能
- 64 卡 A100 集群 + 21500 A100-hours:是 70 亿参数级 VLMs 做机器人任务微调的主流算力规模,大批次(2048)训练能让模型学习到更稳定的跨机器人 / 场景 / 任务的特征规律,避免小批次的训练震荡;
- 14 天训练时长:兼顾训练效率与模型性能,是工业界 / 学术界微调千亿 / 十亿级大模型的典型时长。
-
推理核心指标:低显存 + 准实时帧率,完美适配消费级硬件这是 OpenVLA 能落地机器人端边缘部署的核心,也是最亮眼的工程设计:
- 15GB bfloat16 显存占用:NVIDIA RTX 4090(消费级旗舰显卡,24GB 显存)可轻松承载,无需昂贵的服务器 GPU,大幅降低机器人部署的硬件成本;
- 6Hz 推理帧率:机器人实时控制的黄金阈值(一般要求≥5Hz),未启用任何加速手段的情况下达到 6Hz,说明模型做了极致的工程优化,能满足机器人 “观测 – 推理 – 动作” 的实时闭环需求。
- 量化优化:降显存不损性能,进一步适配低配硬件量化是大模型边缘部署的标配技巧,但多数模型量化后会出现性能下降;而 OpenVLA 实现了 “量化无损性能”,这对机器人任务尤为重要 —— 机器人动作预测的精度直接影响任务成败,该设计让模型可进一步部署在更低配的消费级 GPU(如 RTX 3060/3070,8/12GB 显存)上,进一步降低落地门槛。
-
远程推理服务器:解决机器人「本地算力不足」的终极痛点这是 OpenVLA工程化落地的关键创新,直击机器人硬件的核心限制:
- 机器人本体的硬件空间 / 供电有限,几乎无法搭载高性能 GPU(如机械臂、小型移动机器人仅能搭载树莓派、Jetson Nano 等低配计算板);
- 远程推理服务器实现了 **「算力与执行端分离」**:模型在远端高性能服务器 / 云端推理,仅将动作预测结果通过网络推流给机器人,机器人仅需完成 “接收指令 – 执行动作”,无需本地做复杂推理;
- 开源该方案:让其他研究人员 / 工程师可直接复用,大幅降低机器人 VLA 的落地开发成本。
OpenVLA怎么实现Action?
OpenVLA 中机器人动作(Action)的实现,核心是让预训练视觉语言模型(VLM)适配机器人「连续动作执行」的硬件需求,解决了 VLM 原生仅能输出离散文本 Token、无法直接控制机器人的核心问题,整体是**「连续动作离散化→适配 LLM 输出→Token 还原连续动作→硬件执行」的端到端链路,且融入了工程化优化让动作能实时、精准落地到物理机器人/仿真机器人**。
结合前文的核心设计,整个 Action 实现流程分为6个核心步骤,从模型输入到硬件执行闭环,覆盖算法适配、模型训练、工程落地全环节,所有步骤均围绕「简洁性、适配性、实时性」设计,以下是分步详解(含核心技术细节和落地逻辑):
步骤1:动作预测的任务形式化——转化为VLM原生的视觉-语言任务
OpenVLA 首先将机器人连续动作预测这一机器人专属任务,转化为 VLM 天然能处理的视觉-语言序列预测任务,从任务层面消除模型与机器人的适配鸿沟:
- 输入:机器人的视觉观测图像(如相机采集的场景图)+自然语言任务指令(如“抓取桌面的红色杯子”),按 VLM 的输入格式拼接为「视觉特征+语言特征」的跨模态序列;
- 输出目标:不再是自由文本,而是与机器人动作维度一一对应的离散 Token 序列(如机械臂有7个关节维度,就输出7个动作 Token);
- 核心目的:让预训练 Prismatic-7B VLM 无需重构核心架构,仅通过微调即可学习「视觉-语言→机器人动作」的映射关系,大幅降低模型改造成本。
步骤2:核心适配——机器人连续动作的离散化处理
这是 OpenVLA 实现 Action 的最关键步骤,因为 VLM 的 LLM 骨干(Llama 2)仅能输出离散 Token,而机器人执行的是连续动作值(如机械臂关节角度:-1.57~1.57 rad、移动机器人线速度:0~0.5 m/s),必须通过离散化实现“格式转换”,具体规则严格贴合机器人任务需求:
- 按维度独立离散化:将机器人的N维连续动作(如机械臂7维、移动机器人3维)拆分为N个独立的一维连续值,每个维度单独处理(避免不同维度的动作值范围差异相互干扰);
- 256个等宽区间(bins)划分:每个一维动作值被均匀划分为256个bins,最终转化为0~255的离散整数(N维动作即得到N个0-255的整数,对应后续N个动作 Token);
- 1/99分位数定区间边界:摒弃传统的「最小-最大值边界」,改用训练数据中动作值的1st~99th 分位数作为离散化区间的上下限,剔除异常动作值(如机器人机械故障、数据采集误差导致的极端值),避免正常动作值被压缩在少数bins中,保证动作离散化的有效粒度(即还原后的连续动作精度足够支撑机器人任务)。
举个例子:若机械臂某关节的动作值在训练数据中的1/99分位数为-1.0~1.0 rad,bin宽度则为 (1.0 – (-1.0))/256 = 0.0078 rad/bins;离散整数128对应还原值为 -1.0 + 128×0.0078 = 0 rad,整数255对应1.0 rad,实现「连续值→整数」的精准映射。
步骤3:LLM词表适配——将离散整数映射为LLM可输出的动作Token
离散化得到的0~255整数,需要进一步映射为 Llama 2 分词器能识别并输出的Token,解决了 Llama 分词器「特殊 Token 不足」的问题,具体实现简洁且无性能损失:
- 分词器限制:Llama 2 分词器仅为微调新增 Token 预留100个「特殊 Token」,远不足以承载256个动作 Token;
- 解决方案:秉持简洁性原则,直接覆盖Llama分词器词表中256个使用频率最低的Token(词表最后256个),将其替换为自定义的动作 Token,一一映射0~255的离散整数;
- 核心优势:无需重新训练分词器(重新训练会破坏分词器与 Llama 2 预训练的对齐关系),且低频 Token 在常规文本/视觉-语言任务中几乎不出现,替换后不影响模型的语言理解能力。
至此,机器人的N维连续动作,已完全转化为 VLM 可输出的N个动作 Token 序列,模型层面的适配全部完成。
步骤4:模型训练——让VLM精准学习「视觉-语言→动作Token」的映射
基于上述适配,OpenVLA 以预训练 Prismatic-7B 为骨干做针对性微调,训练目标和损失函数设计均围绕「动作预测精度」优化,避免模型丢失预训练能力:
- 训练目标:沿用 VLM 原生的下一个 Token 预测(next-token prediction),让模型学习在输入「视觉图像+语言指令」后,按顺序输出对应的动作 Token 序列;
- 损失函数:仅对预测的动作 Token 计算交叉熵损失,对视觉-语言输入部分不计算损失;
- 核心目的:固定模型对「视觉-语言」的理解能力(复用 Prismatic-7B 的跨模态对齐能力),让微调的梯度仅更新与「动作 Token 预测」相关的参数,提升训练效率和动作预测的精准度。
训练算力为64卡A100集群、batch size=2048,保证模型能学习到多样化具身载体/场景/任务的动作规律,实现“开箱即用”的多机器人控制。
步骤5:推理阶段——动作Token还原为机器人可执行的连续动作值
模型训练完成后,推理时的核心逆操作是将输出的动作 Token 序列,还原为机器人硬件能执行的连续动作值,这是离散化的逆过程,且全程保证实时性:
- Token→离散整数:将模型输出的动作 Token 映射回0~255的离散整数(基于步骤3的Token-整数映射关系);
- 整数→连续动作值:根据训练时每个动作维度的分位数边界和bin宽度,计算还原公式:
连续动作值 = 1st分位数 + 离散整数 × bin宽度
- 工程化优化:推理时采用bfloat16精度(仅占15GB显存),未加速时单张RTX4090可达6Hz帧率(每秒输出6组连续动作),满足机器人「观测-推理-动作」的实时闭环需求(机器人实时控制的黄金阈值为≥5Hz);同时支持量化优化(INT8/INT4),进一步降低显存占用且不损失实际任务性能,适配更低配的消费级GPU。
步骤6:动作落地——连续动作值发送至机器人硬件执行(本地/远程两种方式)
这是 OpenVLA 动作实现的最后一环,解决了机器人「本地算力不足」的核心痛点,提供本地部署和远程部署两种工程化方案,让动作能落地到物理机器人/仿真机器人:
方案1:本地部署——消费级GPU直连机器人控制器
- 适用场景:机器人配套有消费级GPU(如RTX4090/3090)或高性能边缘计算设备(如Jetson AGX Orin);
- 执行流程:推理得到的连续动作值,通过机器人通信协议(如ROS/ROS2、TCP/IP、串口)直接发送至机器人的运动控制器,控制器将动作值解析为电机/执行器的控制信号,驱动机器人完成动作(如机械臂关节转动、移动机器人轮速调节);
- 核心优势:低延迟,无需网络依赖,适配对实时性要求极高的任务(如精密抓取)。
方案2:远程部署——远程推理服务器推流动作值(核心落地方案)
这是 OpenVLA 针对机器人硬件限制设计的关键工程化创新,也是实际落地的主流方案:
- 机器人痛点:物理机器人(如机械臂、小型移动机器人)的空间、供电、算力有限,无法搭载高性能GPU,仅能配备低配计算板(如树莓派、Jetson Nano);
- 执行流程:
- 机器人将视觉观测图像+语言指令通过网络发送至远程VLA推理服务器(搭载GPU集群/高性能服务器);
- 服务器端运行OpenVLA模型,推理得到连续动作值后,实时远程推流至机器人端;
- 机器人低配计算板仅负责“接收动作值→转发至运动控制器→执行动作”,无需做任何复杂推理;
- 核心优势:彻底分离「算力端」和「执行端」,让低配机器人也能享受大模型的推理能力,且服务器端支持多机器人同时接入,大幅降低部署成本;
- 开源支持:该远程推理方案随OpenVLA源码一同开源,可直接复用,无需重复开发。
OpenVLA动作实现的核心设计亮点
- 端到端适配:无需重构VLM核心架构,仅通过「离散化+词表替换+针对性微调」实现从模型到机器人的动作适配,简洁且易复现;
- 精度与适配性平衡:256 bins离散化+1/99分位数划分,既保证了动作还原的精度,又避免了异常值的干扰,适配不同机器人的动作空间;
- 工程化落地友好:低显存(15GB bfloat16)、准实时帧率(6Hz)、量化无损性能,让模型能运行在消费级GPU上,大幅降低硬件门槛;
- 解决核心痛点:远程推理服务器方案彻底解决了机器人本地算力不足的问题,是OpenVLA能落地到实际物理机器人的关键。
简单总结:OpenVLA 的 Action 实现,本质是**「为机器人动作量身定制的VLM序列预测」**——通过离散化让连续动作适配VLM的输出逻辑,再通过工程化优化让模型推理的动作能实时、精准落地到机器人硬件,最终实现「语言指令→视觉理解→动作执行」的机器人端到端控制。
这篇OpenVLA论文笔记真的超有料!不仅直白点出了当前相关技术在泛化能力上的短板,还给出了融合视觉-语言模型的清晰解决方案,连落地应用的阻碍都分析得明明白白,帮我快速理清了核心思路,太实用啦!感谢作者的用心整理,期待更多干货分享~